
天眼查字体反爬应对
反爬场景
某些网站为了保护数据不被爬虫获取,会使用字体反爬来阻碍爬虫。具体的现象是用户肉眼看到的内容和接口返回是不同的。下面以一张GIF图展示天眼查的字体反爬:
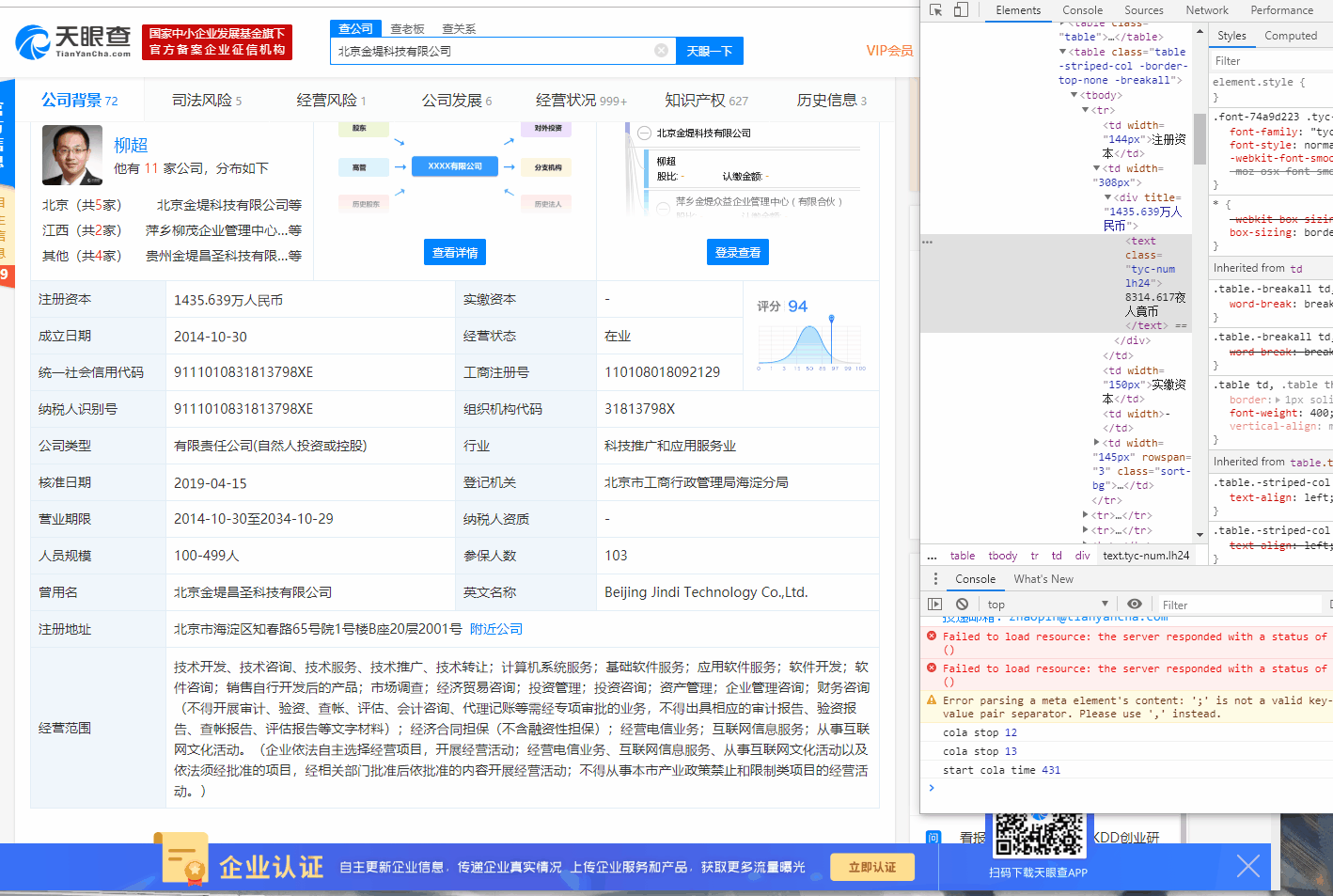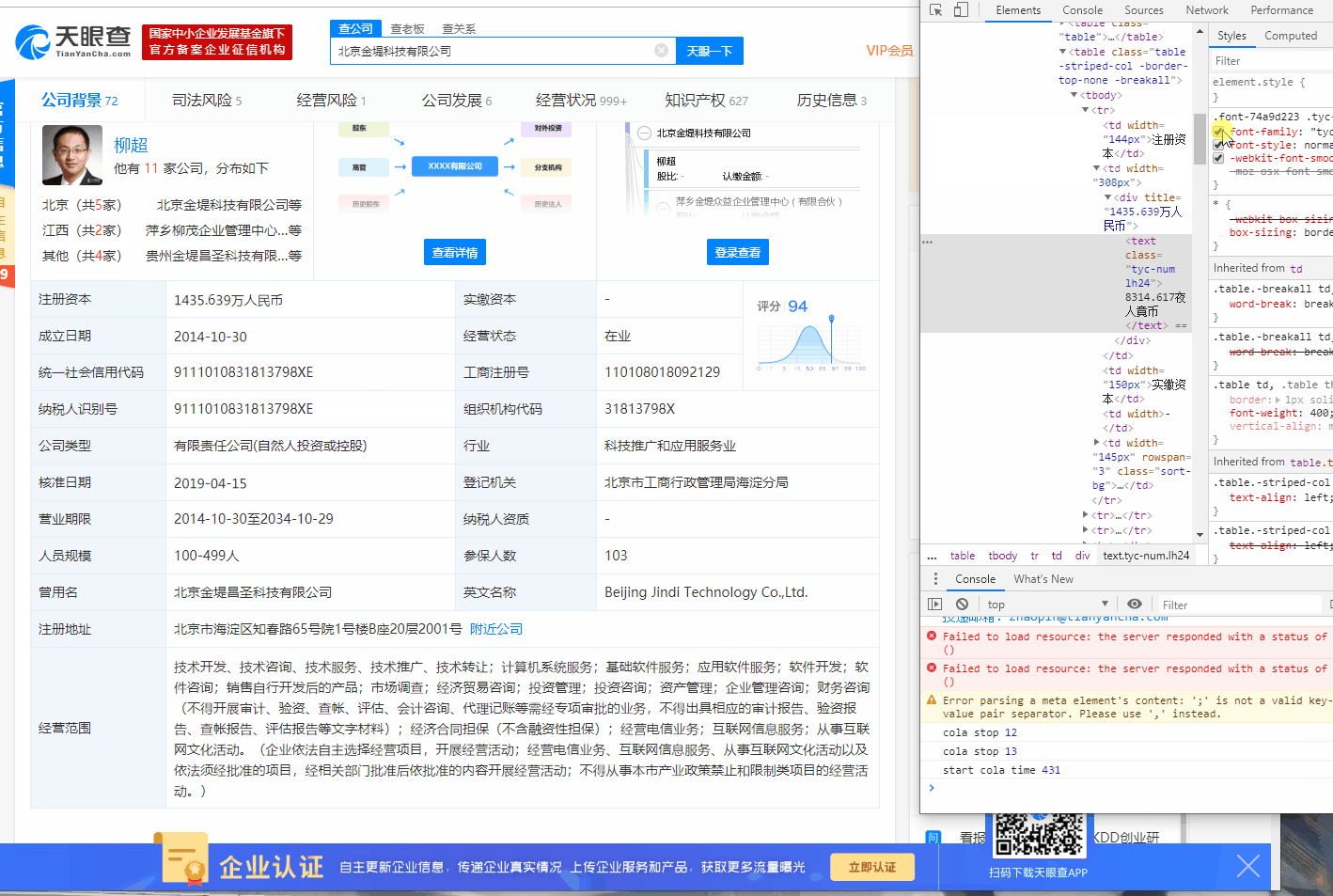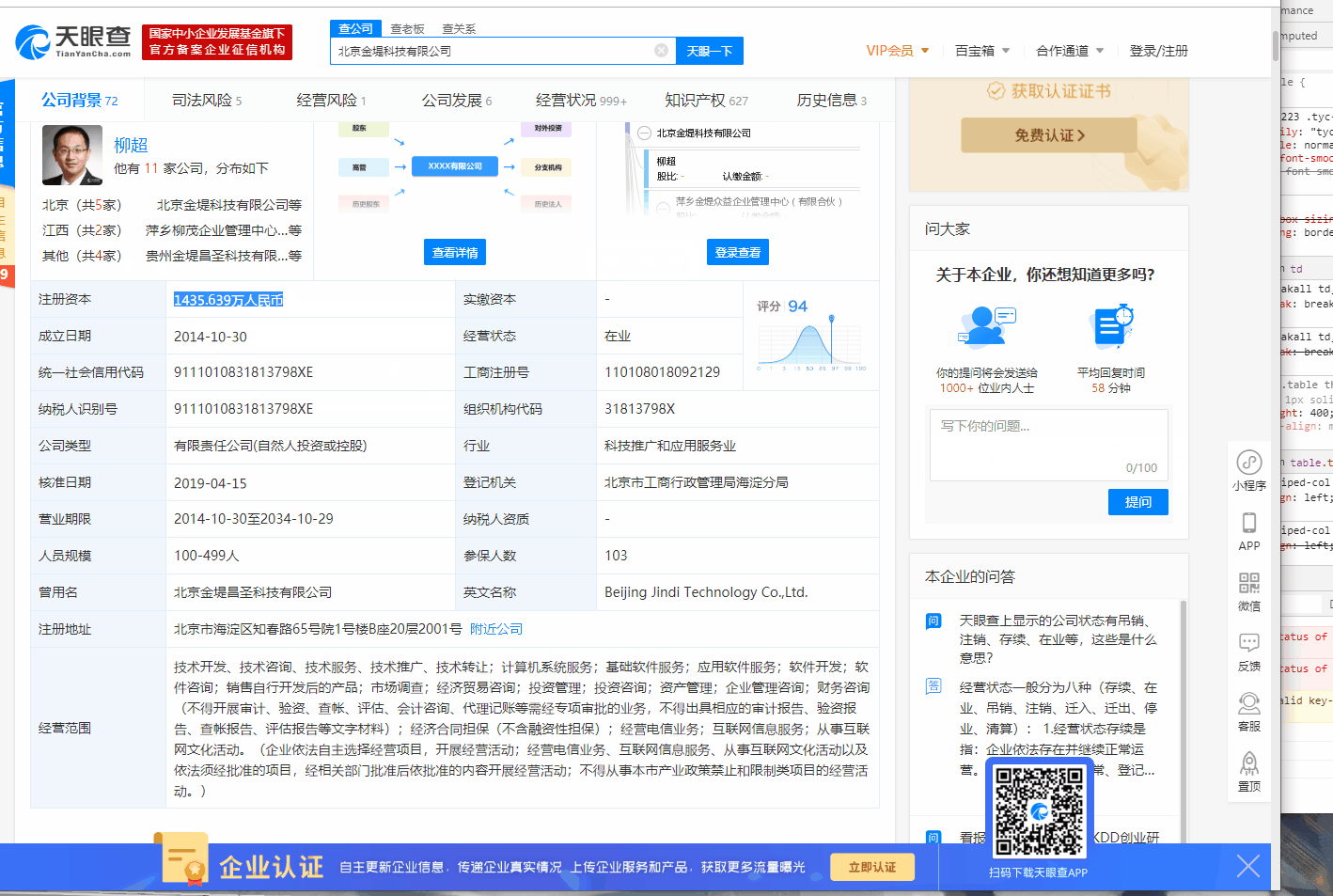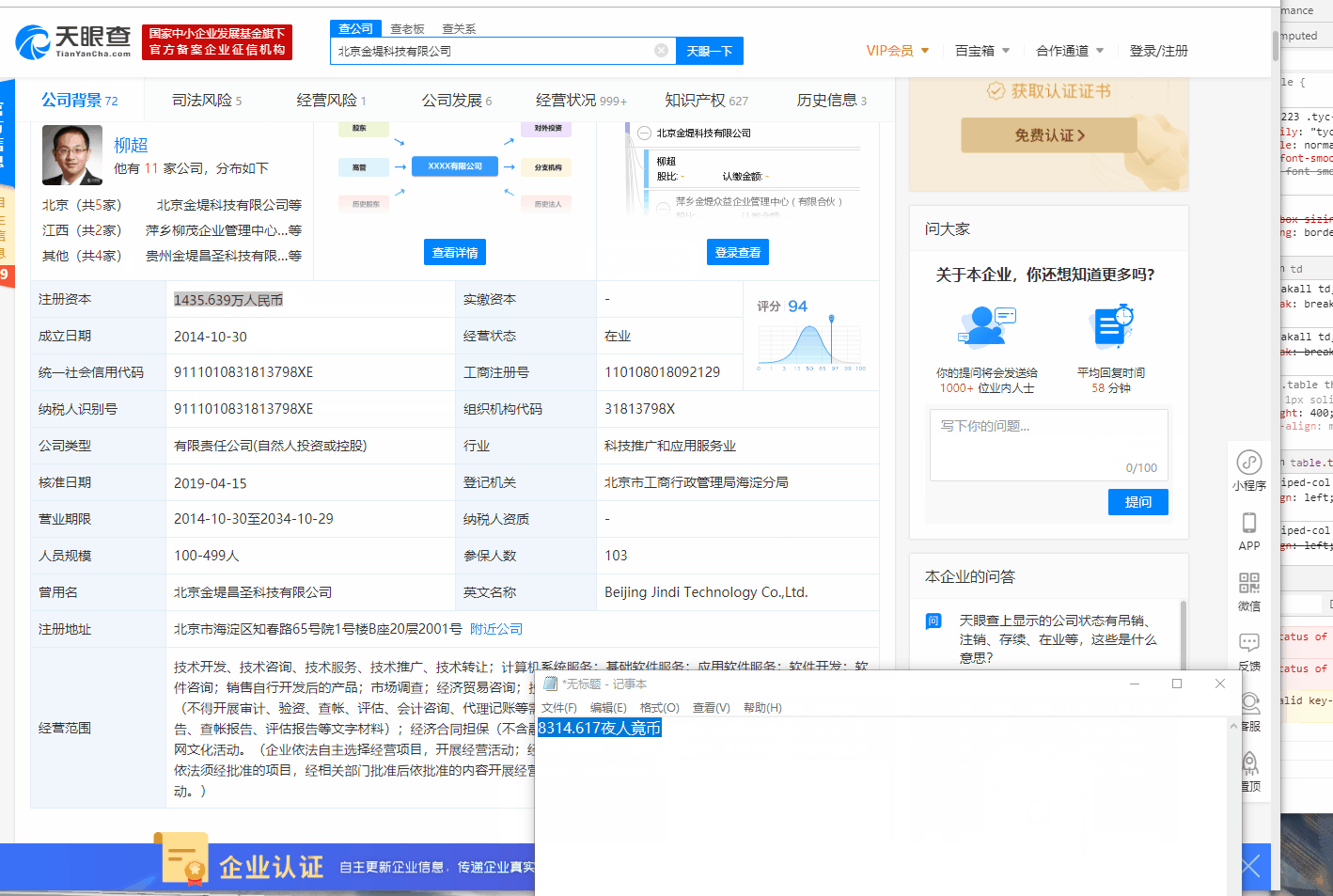
可以看到,当取消了字体渲染的样式之后,页面的内容变了,而直接复制网页上的文本,得到的文字也是错误的。
搜索了一下,这个反爬技术还是有专利的:
CN105812366A_服务器、反爬虫系统和反爬虫验证方法
分析过程
首先观察发现当取消字体渲染时,只有注册资本,成立时间,经营范围这三个字段的数据产生了变化,审查元素后可以看到,只有使用了"tyc-num lh24"类标签的元素才会应用字体渲染。知道是字体反爬后,目标页很明确了。抓包并过滤数据包,只显示字体文件,可以找到关键的字体。如下图:

从Chrome控制台的预览处可以看到,至少数字部分已经打乱。为了直观体现,这里找一张正常的字体进行对比。下面这张图是淘宝登录页面的字体预览:

下面借助百度的字体编辑工具,查看中文部分,工具地址
从之前的gif中我们可以看到,肉眼见到的"技"字是通过"商"字转换而来的,我们在工具中找到"技",注意这里要看图片框呈现出来的字体轮廓,不要直接去对unicode编码。

可以看到字体轮廓对应的unicode编码为"$5546",将unicode转化为中文,得到结果,正是"商"字:

那么,整套的解决思路就有了,即:
- 解析字体文件,得到unicode和字体轮廓的映射关系
- 将字体轮廓转化为图片
- 使用OCR等技术识别字体轮廓,得到最终结果
字体轮廓可以存储起来,例如放到Redis里,下次碰到相同的字体轮廓直接得到结果,避免重复识别。
实现展示
得到Unicode和字体轮廓的映射关系
即将woff格式的字体文件转化为xml
python下可以直接使用fontTools,使用示例:
woff-xml
也可以用百度的字体工具直接导出:

导出结果如下:

其中d值就是我们要的字体轮廓
字体轮廓转图片
这一步熟悉svg绘图的朋友会比较容易些,当时对于没有接触过的爬虫来说可能有点困难,不过我们这边刚好找到一个现成的轮子。实现效果如下:

字体轮廓识别
这一步就不赘述了,现成的API很多,而且对应工整的印刷体识别效果也很好。
API封装调用展示
直接上图:
